GS1 существенно изменил подходы к построению каталогов мастер-данных. Высокие идеи, заложенные в основу сети GS1 GDSN, были сильно реформированы и переосмыслены в рамках нового проекта, построенного на той же основе — TSD (Trusted Source of Data). И значительно приблизились к потребительским реалиям. Так сказать, стали ближе к народу, который ходит покупать в магазины.
В рамках TSD предполагается, по-возможности, гармонично учесть интересы рыночных игроков и отраслевых организаций, в качестве которых выступают:
- агрегаторы данных TSD;
- владельцы брендов и торговых марок. Например, производители товаров и торговые сети, которые выставляют на полки товары под СТМ (собственной торговой маркой);
- прошедший сертификацию, пул провайдеров сети GDSN, которая, по всей вероятности, станет своего рода «костяком» для TSD. По крайней мере — на первом этапе;
- сторонние контент-провайдеры «третьего уровня» — маркетинговые агентства, непосредственные изготовители СТМ, всевозможные операторы, в т.ч. EDI. В рамках TSD они могут действовать с ограничениями, предварительно установив отношения с агрегаторами и владельцами брендов, расположившихся, так сказать, на «первом и втором» уровне;
- интернет-провайдеры, снабжающие потребителей информацией (Internet application providers, IAPs);
- прочие структуры, связанные с GS1: ее головной офис и членские организации.
Раньше, со стороны GS1 мы видели некую попытку стандартизировать все данные и собрать их в рамках сети GDSN. Сейчас же мы уже наблюдаем несколько иной подход. На смену парадигме, построенной вокруг идеи концентрации данных, пришла концепция децентрализации и синхронизации структурированной информации, собранной из различных источников. Что видно на схеме, изображающей основные, рамочные принципы построения фреймворка для новой сети обмена данными.
Организация работы в рамках TSD (GS1 Trusted Source of Data framework)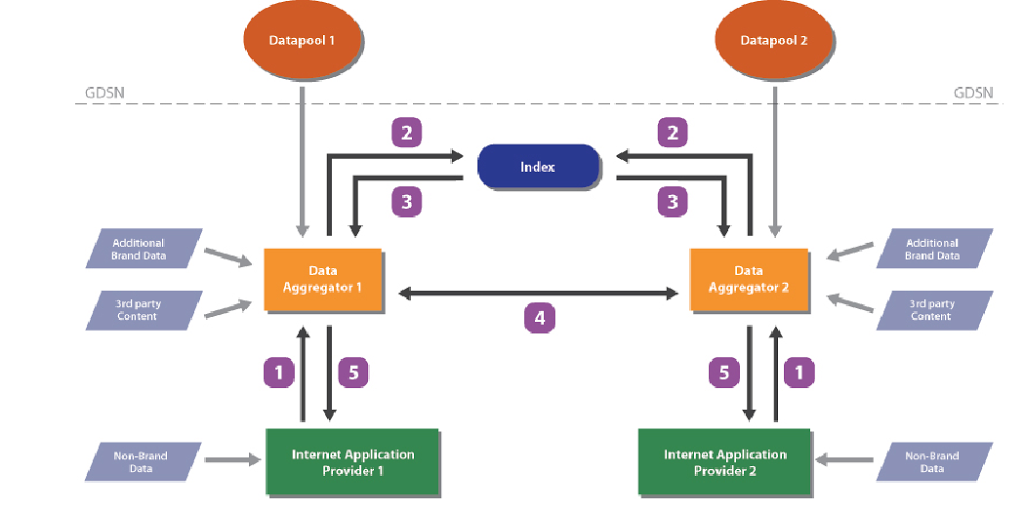
Вознесенная на самый верх схемы GDSN, является системообразующей доминантой для всего процесса, выстраиваемого в рамках TSD. Скажем больше — без GDSN сделать «с нуля» TSD было бы, наверное, весьма затруднительно. Попыток придумать что-то вроде TSD сегодня много, но, — благодаря GDSN, — у GS1 есть некое отчетливое «стартовое преимущество». Как бы там ни было, подвергшийся некоторой модернизации дух GDSN незримо витает надо всею сетью TSD.
Базы данных GDSN, служат на начальных этапах нового проекта, в качестве одного из основных источников стандартизированных сведений о товаре, идентифицируемого при помощи «логистического» кода GTIN. В общем виде, процесс обмена информацией в рамках TSD строится в 5 этапов, изображенных на приведенном выше рисунке стрелками и цифрами. Которые означают:
- Отправка кода GTIN от провайдера к агрегатору;
- Запрос (по данному GTIN) в хранилище индексов;
- Получение из хранилища URL того агрегатора, у которого уже имеется или же появилась новая, дополнительная информация по данному GTIN;
- Синхронизация данных между агрегаторами;
- Получение ответа, привязанного к отправленному коду GTIN, содержащему полный набор атрибутов, накопленных в распределенной системе в связи с данной товарной единицей.
- Остальные, “непронумерованные” стрелки на рисунке показывают то, как происходит взаимодействие прочих сторон. Посильно участвующих в процессе непрерывного “обогащения” данных о товарах.
Таким образом, новые сведения стекаются в систему обмена мастер-данными изо всех доступных (и надежных) источников. Причем, обратившийся с запросом потребитель гарантированно получает полную и самую свежую информацию о товаре.
Процесс синхронизации данных между агрегаторами чем-то отдаленно напоминает работу клиентского ПО, собирающего по запросу пользователя новостной контент с сайтов, представленных в XML-форматах RSS. В рамках такой аналогии, можно сказать, что потребитель узнает о товаре все самые последние «новости».
Подчеркнем, что в 2013 году данный механизм синхронизации, обеспечивающий глобальную интероперабельность, запускать в работу, по плану, не предполагалось. В целом же план был таков:
- В 2011 году, согласно данному плану, был, в частности, проведен черновой, предварительный тест, в котором приняли участие более 30 владельцев брендов с 900 видами производимых товаров. При этом, в качестве агрегаторов и провайдеров выступили по 5 компаний. Отчет по результатам теста был опубликован в начале последовавшего, 2012 года.
- В 2012 году предполагалось разработать глобальные стандарты, обеспечивающие интероперабельность в рамках сети обмена TSD. Нужно было создать рабочее описание проекта, выбрать локальных агрегаторов данных, привлечь через канал выставок и конференций владельцев продуктовых брендов.
- В 2013 году планировалось опубликовать глобальное руководство для внедрения и фреймворк. Эти документы позволяли начать практическую работу. Что и было сделано: в конце 2013 года в сети TSD появился первый агрегатор.
Фреймворк будет иметь настоящую практическую ценность в том случае, если число воспользовавшихся им “брендодержателей” и провайдеров интернет-приложений достигнет некого критического уровня. Чтобы облегчить прохождение ранних стадий проекта, число атрибутов (пищевых и «питьевых») продуктов было ограничено до 6 основных и 19 вспомогательных (показывающих питательную ценность и т.п.).
Логично, что брендодержатели окажутся со временем больше всех прочих заинтересованными в том, чтобы информация об их торговых марках была наиболее полной. Хотя на начальной стадии и не ставится такой цели, хозяева брендов, тем не менее, уже сейчас могут дополнить состав атрибутов своими, дополнительными. Необходимыми, например, для того, чтобы удовлетворить требованиям локального регулятора в той или иной стране.
Сбор такого рода «факультативных» данных, пока что является, — по вполне, впрочем, понятной причине, — наиболее туманной частью приведенной выше схемы. Как мы видим на рисунке, агрегаторы могут получать дополнительные данные непосредственно от владельцев брендов. Брендодержатели, в свою очередь, обязаны заключить соответствующее соглашение с одним или несколькими такими TSD-агрегаторами. Иначе данные от них в сеть обмена через канал агрегатора не попадут.
Можно предположить, что монетизация проекта будет в значительной мере построена на данном обстоятельстве — естественном интересе производителей распространять сведения о своих товарах везде, где только возможно и, тем более, явно целесообразно.
Попытка не пытка. Главное не обольщаться. Делать-то все это кто будет? И кто проплатит?